If you’d like to export this presentation to a PDF, do the following
Toggle into Print View using the E key.
Open the in-browser print dialog (CTRL/CMD+P)
Change the Destination to Save as PDF.
Change the Layout to Landscape.
Change the Margins to None.
Enable the Background graphics option.
Click Save.
This feature has been confirmed to work in Google Chrome and Firefox.
Bivariate Relationships
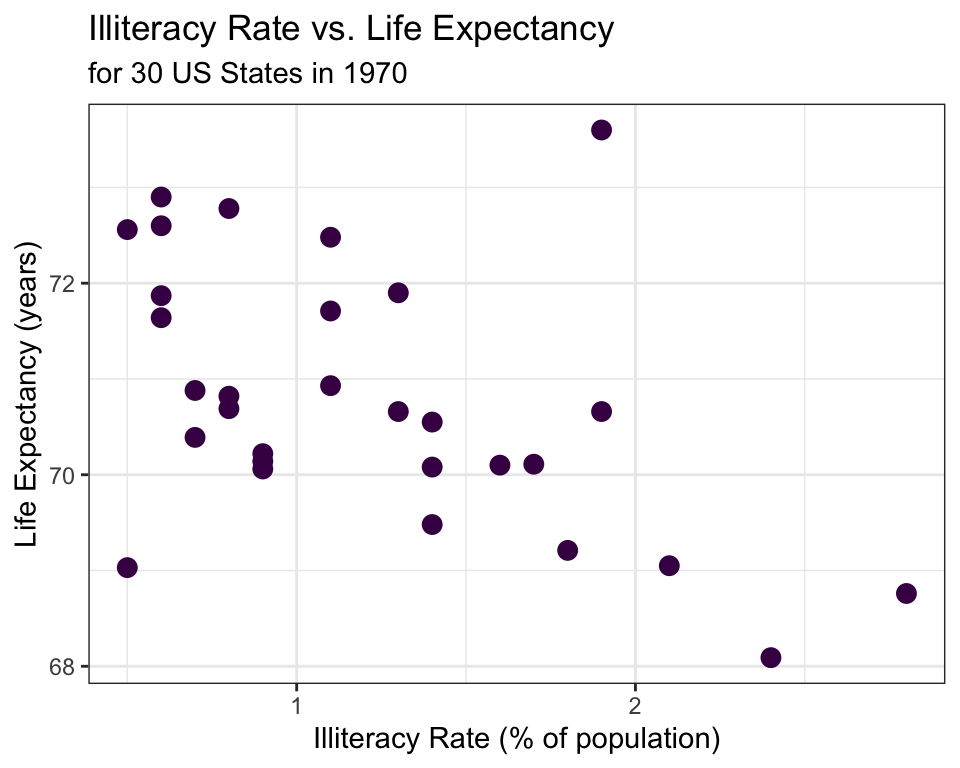
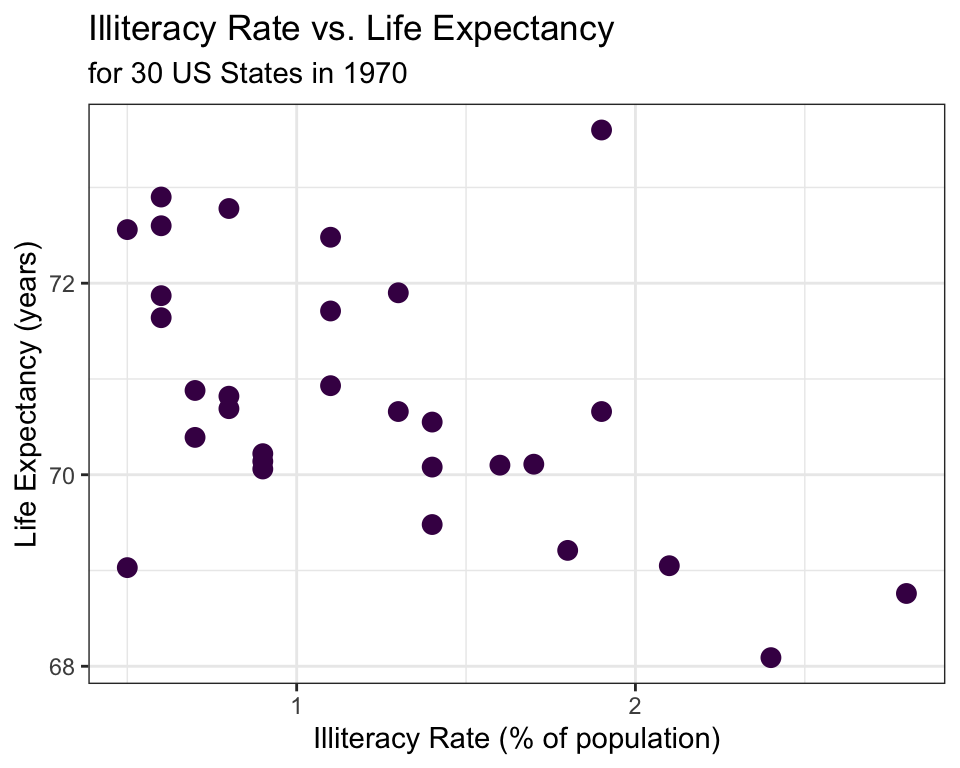
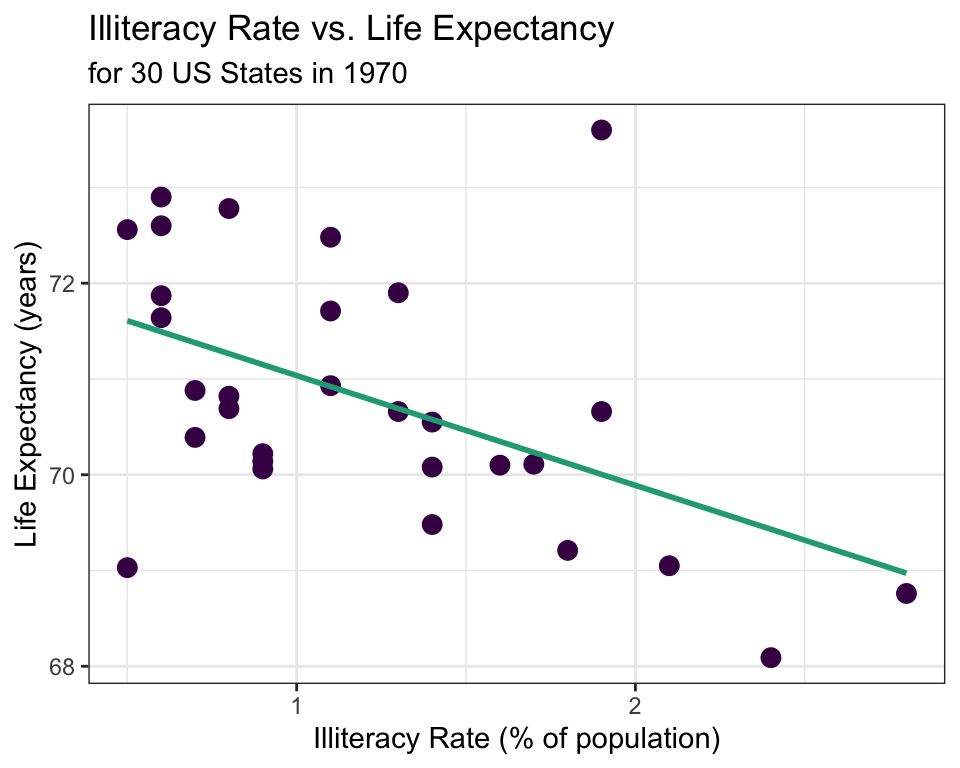
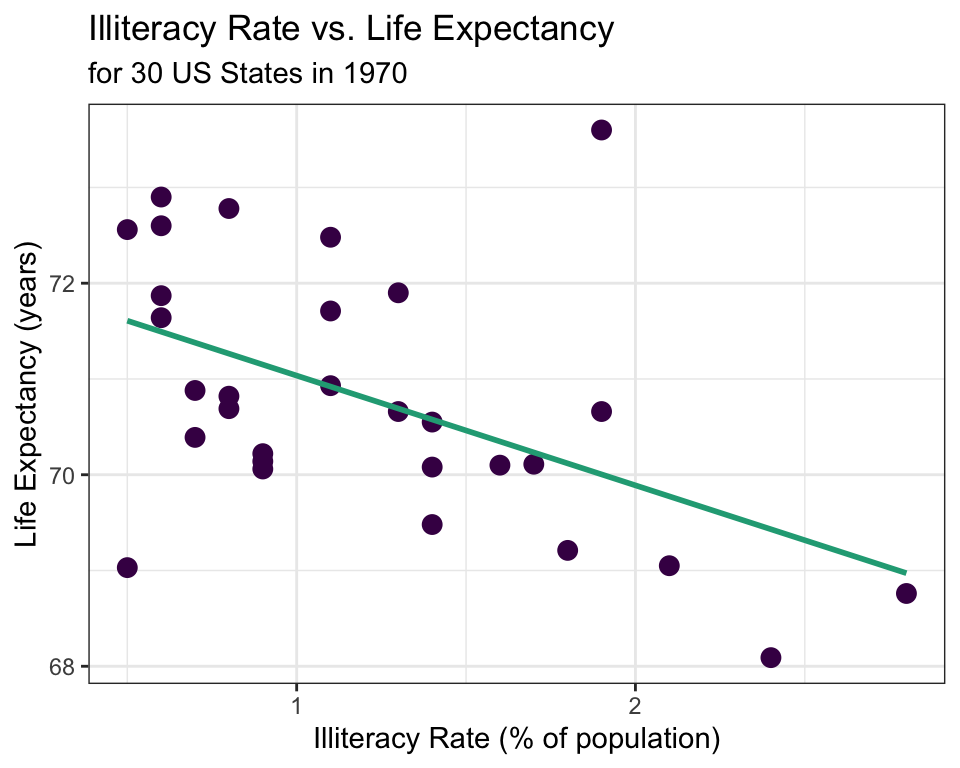
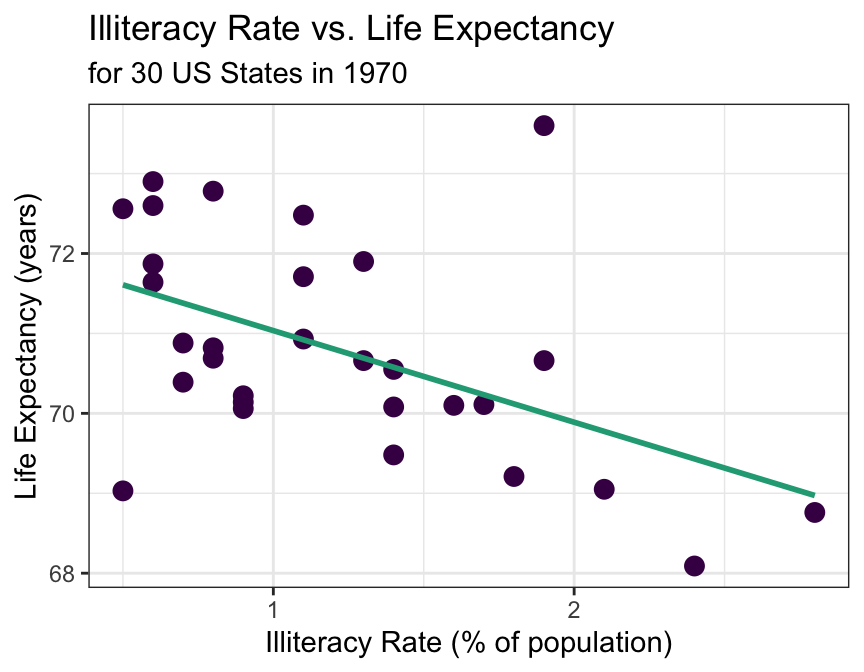
✍️ Describe the relationship between illiteracy rate and life expectancy shown in the scatterplot above.
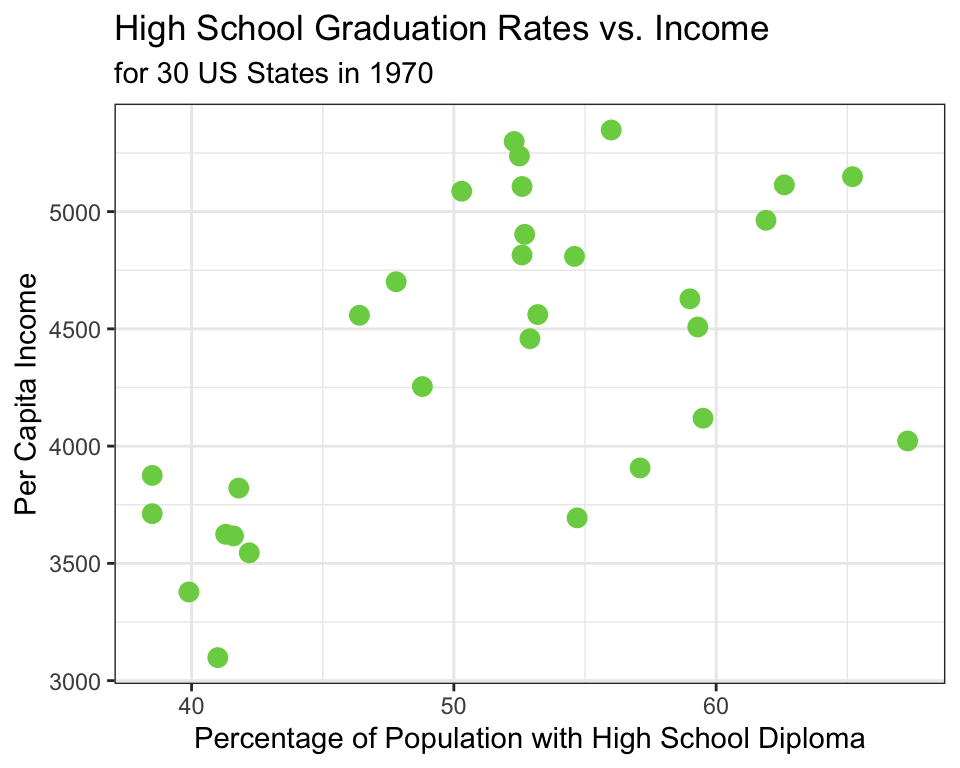
🗣 Describe the relationship between high school graduation rate and income using the scatterplot above.
00:30
Explanatory and Response Variables
When discussing bivariate relationships, it is common to treat one variable as the explanatory and one as the response.
Explanatory Variable
Response Variable
May help to explain or predict changes in the response variable.
Quantitative
Sometimes referred to as
\(x\) variable
independent variable
predictor variable
The variable to be estimated or predicted
Quantitative
Sometimes referred to as
\(y\) variable
dependent variable
Example 📖
If we are interested in trying to model (e.g., explain) life expectancy using illiteracy rate in 1970, which variable should we treat as the explanatory? Which variable should we treat as the response?
Answer in Poll Everywhere
pollev.com/erinhowardstats
Measuring Linear Strength
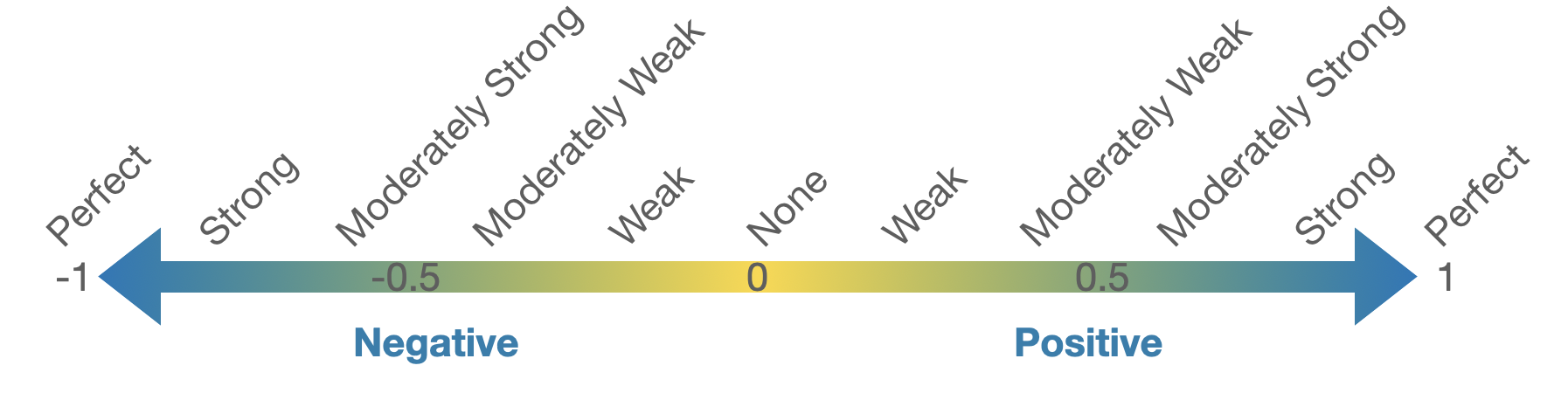
The correlation coefficient, \(R\), measures the strength of a linear association between two quantitative variables.
The correlation between two quantitative variables will always be a value between -1 and 1.
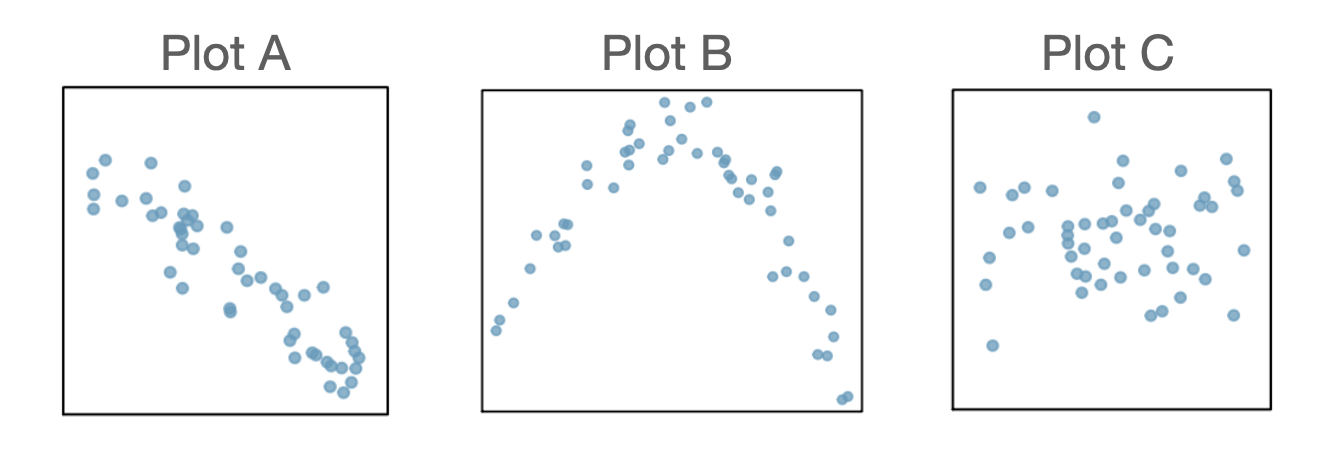
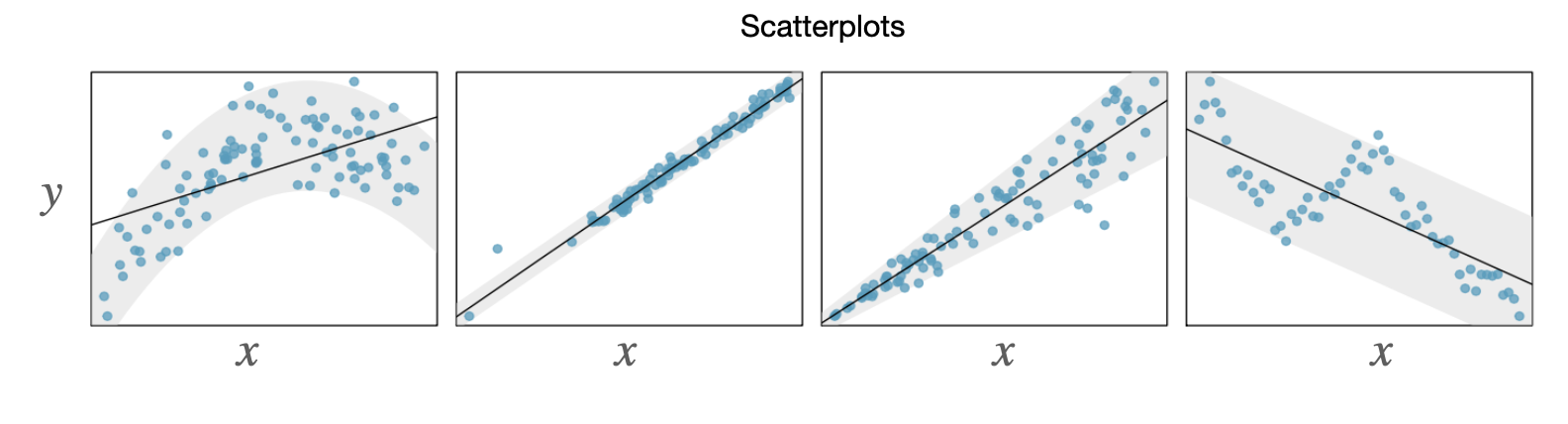
For each of the scatterplots below, estimate the correlation coefficient for the relationship between the explanatory and response variables.
Simple Linear Regression
Simple linear regression is the statistical method for fitting a line to describe the relationship between two quantitative variables.
We want to find a line of the form \(\hat{y} = b_0 + b_1 x\)
What characteristics would the “line of best fit” have?
Simple Linear Regression
Open the link: https://beav.es/cTp (also found in the Quick Links module on Canvas called “SLR Demo”)
Try to find the line that best fits the data by adjusting the sliders below \(b_0\) and \(b_1\).
🗣 Compare your values of \(b_0\) and \(b_1\) to somewhere nearby. Discuss how you chose the values of \(b_0\) and \(b_1\).
02:00
Residuals
The residual of an observation is the difference in the observed response, \(y_i\), and the predicted response based on the model fit, \(\hat{y}_i\).
\(e_i = y_i - \hat{y}_i\)
Least Squares Regression Line
The least squares regression line (LSRL) is calculated by finding the line that minimizes the sum of the squared residuals.
When fitting the LSRL, we generally require:
Linearity - the data should indicate a linear trend
Nearly normal residuals - the residuals should be approximately normally distributed
Constant variability - the variability of the points around the line should be roughly constant
Independent observations
The above conditions are generally checked using a residual plot (coming up…)
If the above conditions are met, we can fit the LSRL using the following estimates \(b_1 = \frac{s_y}{s_x}R\) and \(b_0 = \overline{y} - b_1\overline{x}\)
In practice, we compute these estimates using R. Coming up…
Interpreting the LSRL
\[ \hat{y} = b_0 + b_1 x\]
Interpreting the intercept estimate, \(b_0\): the expected value of the response variable when the explanatory variable is equal to 0.
Interpreting the slope estimate, \(b_1\): For a one unit increase in the explanatory variable, we expect the response to change by \(b_1\).
\[\hat{y} = 72.181 - 1.146x\] where \(\hat{y}\) is the predicted average life expectancy and \(x\) represents illiteracy rate.
Example 📖
The LSRL that best fits the illiteracy rate vs. life expectancy data is
\[\hat{y} = 72.181 - 1.146x\] where \(\hat{y}\) is the predicted average life expectancy and \(x\) represents illiteracy rate.
Interpret the slope estimate from this LSRL:
Answer in Poll Everywhere (pollev.com/erinhowardstats)
00:45
Basic Predictions from the LSRL
The LSRL can be used to predict the outcome of the response variable for given values of the explanatory variable.
Example 📖
\[\hat{y} = 72.181 - 1.146x\] where \(\hat{y}\) is the predicted average life expectancy and \(x\) represents illiteracy rate.
Predict the average life expectancy in 1970 for a state with an illiteracy rate of 1.4%.
\[\hat{y} = 72.181 - 1.146(1.4) = 70.577\]
Residuals (again)
Recall that the residual is difference in the observed response variable and the predicted response based on the model fit: \[e_i = y_i - \hat{y}_i\]
Example 📖
\[\hat{y} = 72.181 - 1.146x\] where \(\hat{y}\) is the predicted average life expectancy and \(x\) represents illiteracy rate.
Compute the residual for a state that had an illiteracy rate of 1.4% and an average life expectancy of 70.55.
Answer in Poll Everywhere (pollev.com/erinhowardstats)
\[e = 70.55 - 70.577 = -0.027\]
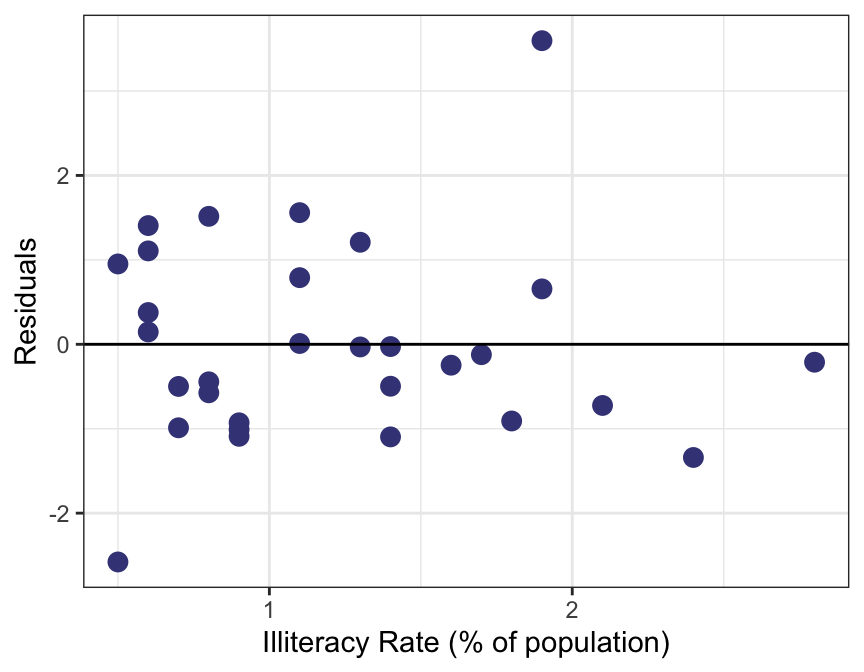
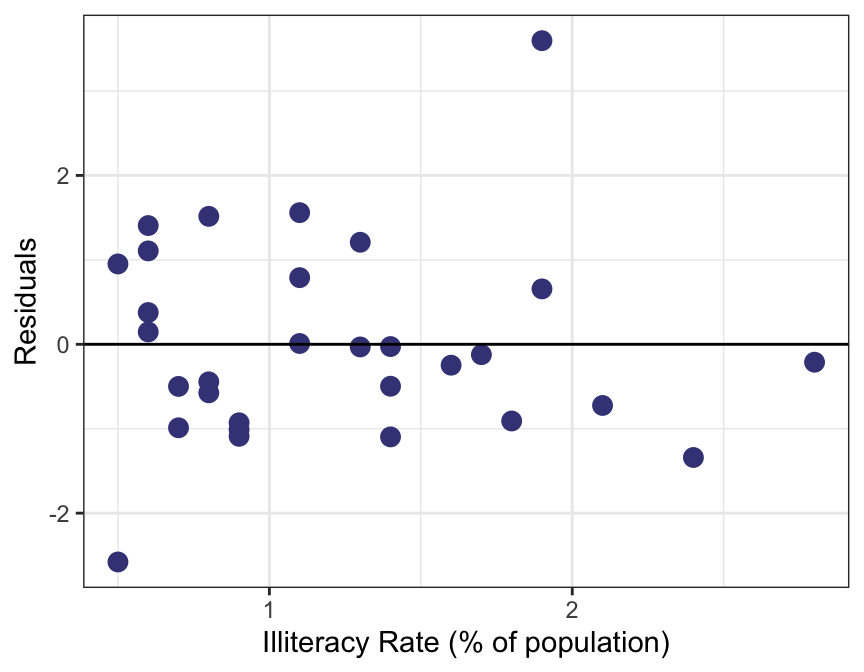
Residual Plot
Recall that to fit the LSRL, we need four conditions to hold (see Least Squares Regression Line slide).
Some of these conditions can be easily checked using a residual plot.
Ideally, when fitting the LSRL, we see no obvious patterns in the residual plot.
If a pattern is visible, it might be an indication that one or more of the LSRL conditions are violated.
Violations of LSRL Conditions
Linearity violated
Nearly normal residuals violated
Constant variability violated
Independence violated
Example 📖
\[\hat{y} = 72.181 - 1.146x\] where \(\hat{y}\) is the predicted average life expectancy and \(x\) represents illiteracy rate.
Are any of the LSRL conditions (linearity, normal residuals, constant variability, or independence) violated for the model that was fit for illiteracy vs. life expectancy?
Prediction & Confidence Intervals
The model predicted that for a state with an illiteracy rate \(1.4\%\), the life expectancy was 70.577 years in 1970.
\[\hat{y} = 72.181 - 1.146(1.4) = 70.577\]
Prediction Intervals for a Single Response Value
We know that this prediction in based on a sample and that a different sample of observations would have likely yielded a slightly different prediction.
We can address the uncertainty in the prediction for this single response value using a prediction interval.
For a single state with an illiteracy rate of 1.4% in 1970, we are 95% confident that the life expectancy was between 68.064 and 73.090 years, with a point estimate of 70.577 years.
Prediction & Confidence Intervals
The Central Limit Theorem tells us that mean values are more predictable than individual measurements.
Consider predicted the mean life expectancy for all states with an illiteracy rate of 1.4%.
The estimate is the same as what we saw previously: \(\bar{y} = 72.181 - 1.146(1.4) = 70.577\).
Confidence Intervals for a Mean Response Value
In addition to the point estimate for the mean life expectancy for all states with an illiteracy rate of 1.4%, we can provide a confidence interval for the mean response value.
We are 95% confident that mean life expectancy in 1970 for all states with an illiteracy rate of 1.4% was between 70.103 and 71.051 years, with a point estimate for the mean response of 70.577 years.
Compare the two intervals. Which one is wider and why do you think this?
We won’t cover anymore of the details of these intervals, but if you want to read more or explore the formulas used to calculate the interval bounds, check out the textbook’s supplemental material.
00:45
R Code for This Week’s Examples
# Open the tidyverse librarylibrary(tidyverse)# Import the dataset, first need to download the data from Canvasstate_30 <-read_csv(file.choose())# Create a scatterplot of the Illiteracy and LifeExp variablesggplot(data = state_30, aes(x = Illiteracy, y = LifeExp)) +geom_point(color ="purple", size =3) +labs(y ="Life Expectancy (years)", x ="Illiteracy Rate (% of population)", title ="Illiteracy Rate vs. Life Expectancy",subtitle ="for 30 US States in 1970") +theme(axis.title =element_text(size =18)) +theme_bw() +stat_smooth(method ="lm",formula = y ~ x, geom ="smooth", se =FALSE, color ="darkgreen")## Calculate the correlation between illiteracy rate and life expstate_30 %>%summarise(cor =cor(Illiteracy, LifeExp))# Estimate intercept and slope for LSRLlm(LifeExp ~ Illiteracy, data = state_30)